About
The workshop and shared task “Semantic Analysis at SEPLN (TASS)” has been held since 2012, under the umbrella of the International Conference of the Spanish Society for Natural Language Processing (SEPLN). TASS was the first shared task on sentiment analysis in Twitter in Spanish. Spanish is the second language used in Facebook and Twitter [1], which calls for the development and availability of language-specific methods and resources for sentiment analysis. The initial aim of TASS was the furtherance of research on sentiment analysis in Spanish with a special interest in the language used in Twitter. Since 2019 it is part of IberLEF (Iberian Languages Evaluation Forum).
Although sentiment analysis is still an open problem, the Organization Committee would like to foster research on other tasks related to the processing of the semantics of texts written in Spanish. Consequently, the name of the workshop/shared task has been changed to “Workshop on Semantic Analysis at SEPLN (TASS)”.
After several years exploring general polarity analysis, with different collections, Spanish variants and a great success of participation, in TASS 2020 we evolved towards emotion classification, with a new collection. In addition, we maintain the main task of general polarity analysis, with some novelties, which are described below.
Task 1: General polarity at three levels
The aim of this original task of TASS is the evaluation of polarity classification systems of tweets written in Spanish and different variants. We propose two subtasks:
- Subtask-1: Monolingual. Training and test using each InterTASS dataset (ES-Spain, PE-Peru, CR-Costa Rica, CH-Chile, UR-Uruguay, MX-Mexico). Any corpora or linguistic resource will be permitted.
- Subtask-2: Multivariant. A new test dataset will be delivered, with tweets extracted from the different subsets of Spain, Peru, Costa Rica, Chile, Uruguay, and Mexico. Again, it will be possible to use any corpora or linguistic resources.
Challenges:
- Lack of context: Tweets are short (up to 240 characters).
- Informal language: Misspellings, emojis, onomatopoeias are common.
- Variants: The training, tests and development corpus contains tweets written in the Spanish language spoken in Spain, Peru, Costa Rica, Chile, Uruguay, and Mexico.
Also as a novelty, the delivered corpora contains only 3 different tags or levels of opinion intensity (P, N, NEU), where NEU will include NONE.
Evaluation measures: accuracy and the macro-averaged versions of Precision, Recall, and F1 will be used as evaluation measures. Systems will be ranked by the Macro-F1 and Accuracy measures.
Task 2: Emotion detection
Understanding the emotions expressed by users on social media is a hard task due to the absence of voice modulations and facial expressions. Our shared task “Emotion detection” has been designed to encourage research in this area. The task consists of classifying the emotion expressed in a tweet as ‘neutral or no emotion’ or as one of the six Ekman’s basic emotions:
- anger (also includes annoyance and rage) can be inferred
- disgust (also includes disinterest, dislike, and loathing) can be inferred
- fear (also includes apprehension, anxiety, concern, and terror) can be inferred
- joy (also includes serenity and ecstasy) can be inferred
- sadness (also includes pensiveness and grief) can be inferred
- surprise (also includes distraction and amazement) can be inferred
The dataset is based on events that took place in April 2019 related to different domains: entertainment, catastrophe, political, global commemoration, and global strike. Since these events are polarized, we have decided to replace the hashtags in the dataset by the keyword “HASHTAG” in order to prevent the automatic classifier from relying on hashtags to categorize the emotion associated with a tweet. Moreover, we replaced the user mentions by @USER.
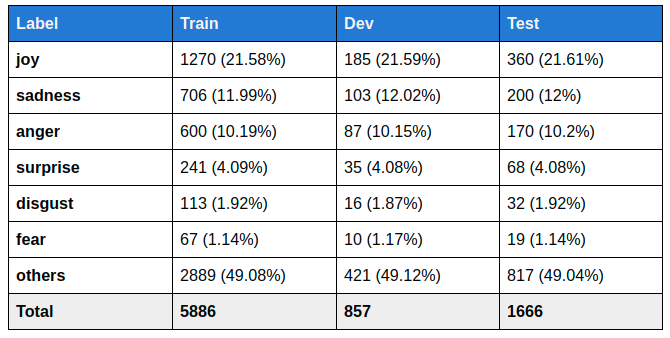
The dataset contains a total of 8,409 tweets written in Spanish. For the task, training, development and test sets will be released.
Next table shows the number and percentage of tweets corresponding to each partition by emotion:
Evaluation measures: accuracy and the macro-averaged versions of Precision, Recall, and F1 will be used as evaluation measures. Systems will be ranked by the Macro-F1 and Accuracy measures.
Challenges:
- Lack of context: Tweets are short (up to 240 characters).
- Informal language: Misspellings, emojis, onomatopoeias are common.
- Multiclass classification: The dataset is labeled with seven different classes.
Schedule
- Release of training and development corpora: Feb 1, 2019
- Release of test corpora:
May 1May 3, 2020 - Deadline for evaluation:
May 12June 1, 2020 - Paper submission:
May 25June 15, 2020 - Review notification:
June 15June 30, 2020 - Camera-ready submission:
July 3July 15, 2020 - Publication: September 2020
- Workshop: Málaga (CEDI 2020), September 2020
Proceedings
The Organization Committee of TASS encourages participants to submit a description paper of their systems. Submitted papers will be reviewed by a scientific committee, and only accepted papers will be published at CEUR, as in previous years. Authors must use this template for describing their systems.
Depending on the final number of participants and the time allocated for the workshop, all or a selected group of papers will be presented and discussed in the Workshop session.
In the following links you can see the proceedings of the previous editions:
Organization
Organizing Committee
- Manuel García Vega (University of Jaén, Spain)
- Manuel Carlos Díaz Galiano (University of Jaén, Spain)
- Miguel Ángel García Cumbreras (University of Jaén, Spain)
- Flor Miriam Plaza del Arco (University of Jaén, Spain)
- Arturo Montejo Ráez (University of Jaén, Spain)
- Salud María Jiménez Zafra (University of Jaén, Spain)
- Eugenio Martínez Cámara (University of Granada, Spain)
- César Antonio Aguilar (Universidad Católica de Chile, Chile)
- Edgar Casasola Murillo (Universidad de Costa Rica, Costa Rica)
- Marco Antonio Sobrevilla Cabezudo (Universidade de São Paulo, Brazil)
- Luis Chiruzzo (Universidad de la República, Uruguay)
- Daniela A. Moctezuma (CentroGeo Aguascalientes, México)
Program Committee
- Erik Cambria (Nanyang Technological University)
- Edgar Casasola Murillo (University of Costa Rica, Costa Rica)
- Fermín Cruz Mata (University of Sevilla, Spain)
- Luis Espinosa Anke (Cardiff University, United Kingdom)
- Yoan Gutiérrez Vázquez (University of Alicante, Spain)
- Lluís F. Hurtado (Polytechnic University of Valencia, Spain)
- Salud María Jiménez Zafra (University of Jaén, Spain)
- María Victoria Luzón García (University of Granada, Spain)
- Mª. Teresa Martín Valdivia (University of Jaén, Spain)
- Manuel Montes Gómez (National Institute of Astrophysics, Optics and Electronics, Mexico)
- Antonio Moreno Ortíz (University of Málaga, Spain)
- José Manuel Perea Ortega (University of Extremadura, Spain)
- Ferrán Pla (Universidad Politécnica de Valencia, Spain)
- Sara Rosenthal (IBM Research, U.S.A.)
- Maite Taboada (Simon Fraser University, Canada)
- L. Alfonso Ureña López (University of Jaén, Spain)